Echo-Gnosis
The name "Echo-Gnosis" combines two concepts from different fields:
Echo: A sound or series of sounds caused by the reflection of sound waves from a surface back to the listener, referencing physical space.
Gnosis: A Greek term for knowledge, specifically an intuitive, direct, or experiential apprehension of reality.
Echo-gnosis: Intuitive spatial knowledge and physical awareness achieved through the continuous sensory feedback of sound.

The Idea
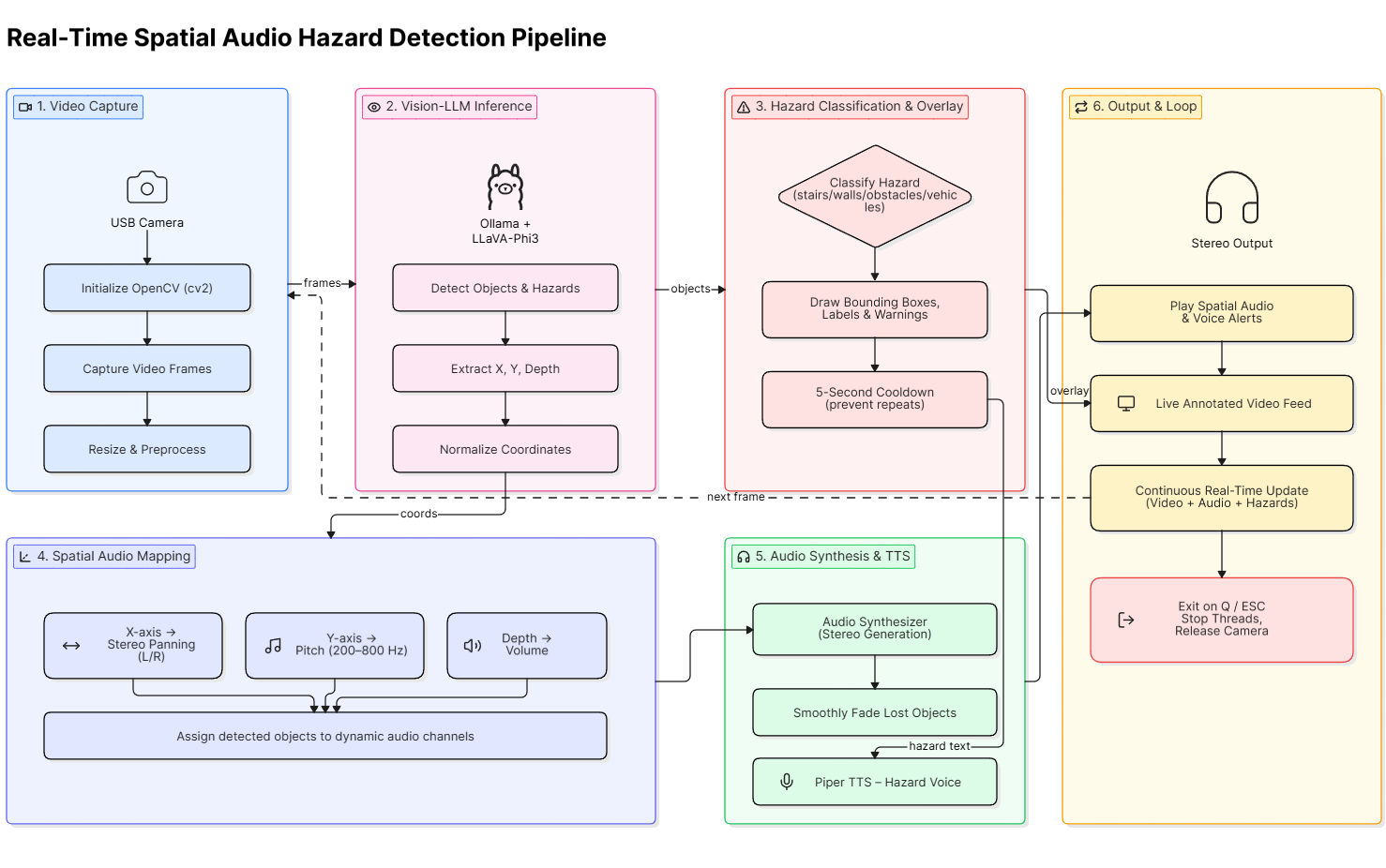
Motivated by the cognitive load blind and low-vision individuals face when navigating unseen spaces, and the overwhelming nature of constant verbal warnings, Echo-Gnosis explores how local Artificial Intelligence can translate the physical world into an intuitive, tactile acoustic map. This application aims to replace jarring, high-latency alerts with a continuous sensory extension tailored specifically for the visually impaired. By feeding a live USB camera stream into a completely local, offline Vision-LLM, the system extracts the physical coordinates of objects and hazards. It then generates a continuous spatial stereo audio environment by modulating pitch, pan, and volume alongside minimal, spoken safety alerts for immediate dangers. The design intent focuses heavily on cognitive ease, privacy, and zero-latency trust, ensuring the technology serves as an invisible guide to help users feel the shape of their physical surroundings and navigate with confidence without relying on the cloud.
Development
Echo-Gnosis was developed with a strict focus on local execution to ensure absolute privacy and physical safety, while exploring a more sensory, human-centric approach to accessibility software for the blind community. The core development involved:
- Platform: Built using Python and OpenCV for the frontend, creating a lightweight, live video GUI overlay that visualizes the AI's understanding of the space in real-time.
- Visual Design: Implements a high-contrast visual feedback loop. Standard objects are tracked with calming green bounding boxes, while immediate hazards (like stairs or walls) trigger bold, red warning banners to communicate danger instantly and clearly to sighted assistants or developers supporting the visually impaired user.
- AI Pipeline: Implemented a local vision workflow using the Ollama Python API. Continuous video frames are analyzed by the llava-phi3 multimodal model to extract spatial coordinates and identify potential physical hazards with low latency.
- Audio Synthesis: Utilizes NumPy and PortAudio to synthesize continuous sine waves mapped dynamically to the object’s coordinates (panning for horizontal placement, pitch for vertical elevation, and volume for depth) creating a tactile auditory landscape that acts as a digital sonic cane.
- Features: Includes real-time spatial sound mapping, Piper TTS for vital spoken alerts featuring built-in cooldowns to prevent auditory fatigue, and an offline-first architecture that guarantees environmental data never leaves the device.
Tech Stack
1. The Core Application
- Python: The core programming language orchestrating the video capture, vision models, and audio threads.
2. Frontend & User Interface
- OpenCV (cv2): Used to handle webcam capture, frame resizing, GUI window creation, and rendering 2D overlay drawings for visual feedback.
3. Backend Orchestration & Vision AI
- Ollama Python Client (ollama): The local server and API library used to route video frames to the Vision-LLM without requiring internet access.
- LLaVA-Phi3 (llava-phi3:latest): A 3.8B parameter multimodal vision model optimized for low-latency visual-text parsing, used locally to "see" the environment and output standard image coordinates.
4. Audio Generation & TTS Engine
- Sounddevice & NumPy: Connects to the host OS audio output for low-level, non-blocking real-time audio thread callbacks, using high-speed mathematical sound wave synthesis.
- Piper TTS: A fast, local neural text-to-speech system using the
en_US-lessac-medium.onnxvoice model to deliver natural-sounding, spoken safety alerts.
5. Hardware Dependencies
- Webcam & Audio: Requires a standard USB camera and stereo headphones (essential for perceiving left/right spatial panning).
Reflection
As a spatial computing prototype, Echo-Gnosis successfully demonstrates how complex multimodal AI can be packaged into a protective, sensory-rich user experience that directly empowers the visually impaired. By focusing on continuous spatial audio rather than relying solely on verbal warnings, the application provides intuitive, tactile feedback that reduces cognitive load and prevents user fatigue during daily navigation. The deliberate choice to run all models locally addresses the critical privacy and latency concerns associated with cloud-dependent accessibility tools. Applying a seamless auditory mapping to physical coordinates proved that machine learning interfaces can act as a natural, sixth sense for blind and low-vision users rather than a utilitarian alarm system. The project validates the concept that dynamic audio synthesis, guided by local vision models, can serve as a profound tool for fostering spatial awareness and true physical autonomy.
What Worked
- The continuous spatial audio synthesis (pan, pitch, volume) created an intuitive sense of physical space and depth without verbal clutter, serving as an effective auditory guide for non-visual navigation.
- The dual-warning system, using ambient tones for general objects and Piper TTS for immediate hazards, effectively balanced situational awareness with critical safety.
- The local Vision-LLM (llava-phi3) successfully extracted accurate coordinates and depth estimations at an acceptable frame rate.
- The 100% offline architecture ensured zero API latency and absolute data privacy, which is absolutely critical for a real-time physical navigation tool.
What Did Not Work / Limitations
- The reliance on continuous local CPU/GPU resources limits the battery life and portability of the system for mobile, on-the-go accessibility.
- Processing latency (under 1.5s per frame) is still present; true human-speed navigation requires even faster visual parsing to feel entirely seamless for a visually impaired user walking at a standard pace.
- No controlled psychological or usability studies were formally conducted with visually impaired individuals to validate the cognitive comfort of the sine-wave frequencies over prolonged, daily use.
- The current auditory output is limited to basic sine waves and could be expanded to more organic, less fatiguing acoustic textures (like wind or water).
Github