Acoustic Chronotope

The phrase "Acoustic Chronotope" combines two concepts from different fields:
- Acoustic: Relating to sound, hearing, or the properties of sound.
- Chronotope: A term introduced by Mikhail Bakhtin. It combines the Greek words chronos (time) and topos (place) and refers to the interconnected relationship between time and space in a narrative or experience.
Acoustic chronotope: The experience or representation of time and place through sound.
The Idea
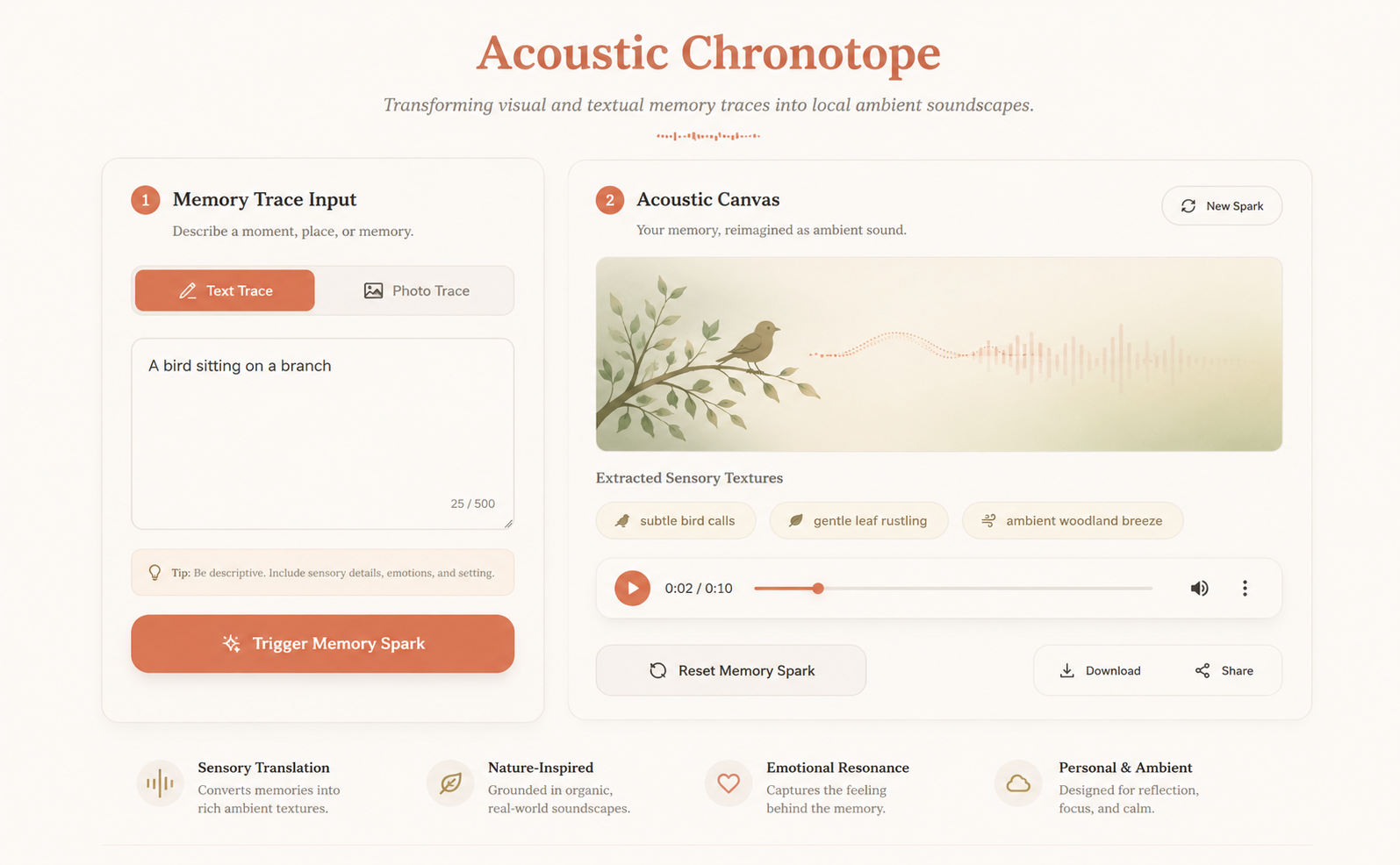
Motivated by the emotional resonance of memory and the unique way sound anchors us to specific moments in time, Acoustic Chronotope explores how local Artificial Intelligence can transform personal journals into immersive acoustic environments. This desktop application aims to turn static text and visual memories into ambient soundscapes. By securely feeding a memory fragment or photograph into a completely local, offline pipeline, the system extracts sensory and emotional markers like weather conditions, location, and atmosphere. It then generates a custom 30 second environmental background audio track, such as distant rolling thunder or a quiet indoor room tone. The design intent focuses heavily on privacy, tactility, and human connection, ensuring the technology serves as an invisible bridge to help users reconnect with the auditory texture of their past experiences without relying on the cloud.
Development
Acoustic Chronotope was developed with a strict focus on local execution to protect the privacy of user memories while exploring a more human and tactile approach to software design. The core development involved:
- Platform: Built using Streamlit for the frontend, heavily customized with CSS to replace standard technical dashboard aesthetics with a warm, human centric journal experience.
- Visual Design: Implements a warm minimalist palette of Linen Cream and rich charcoal, paired with high contrast editorial typography. Generous whitespace and soft structural shadows evoke the physical quality of premium stationery.
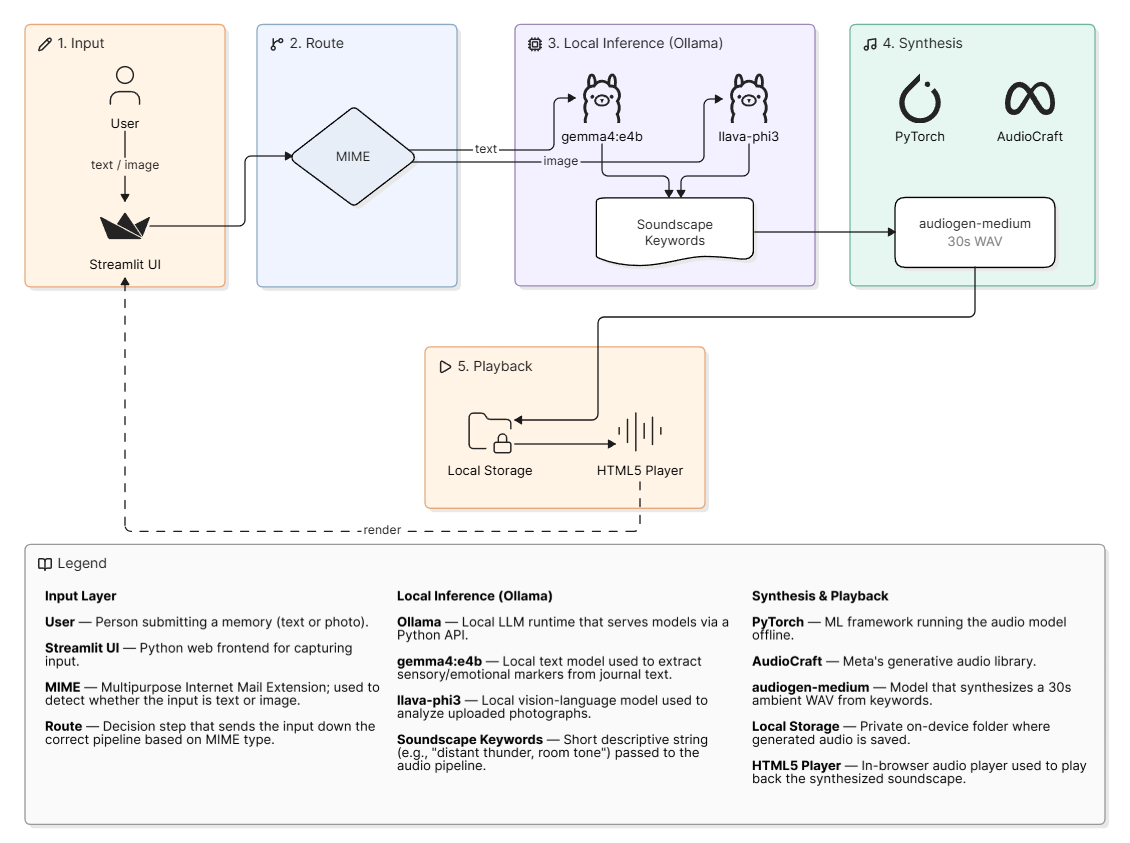
- AI Pipeline: Implemented a dual routing local workflow using the Ollama Python API. Text inputs are processed by the gemma4:e4b model, while image inputs are analyzed by the llava-phi3:latest model to extract descriptive soundscape keywords.
- Audio Synthesis: Utilizes the Meta AudioCraft library running the facebook/audiogen-medium model locally via PyTorch to generate ambient background sounds directly from the extracted keywords.
- Features: Includes an intuitive input canvas for both text and images, contextual processing feedback states to maintain user trust, and a clean HTML5 playback bar for the generated audio, alongside automated local storage management.
Tech Stack
1. The Core Application
- Python: The core programming language tying the models and the frontend together.
2. Frontend & User Interface
- Streamlit (
streamlit): The Python-based UI framework used to build the desktop interface. - Custom CSS: Injected into Streamlit to override the default styling and achieve the "Human Style" design (Linen Cream backgrounds, serif typography, rounded corners).
- HTML5 Web Audio API: Used natively via Streamlit's
st.audiocomponent to render the playback bar for the generated sounds.
3. Backend Orchestration & Text/Vision AI
- Ollama Python Client (
ollama): The local server and API library used to route inputs to the Large Language Models without requiring internet access. - Gemma 4 (
gemma4:e4b): Google's lightweight 4.5B parameter LLM, used locally to process pure text journals and extract sensory soundscape keywords. - LLaVA-Phi3 (
llava-phi3:latest): A 3.8B parameter multimodal vision model (built on Microsoft's Phi-3 architecture), used locally to "see" uploaded images and translate the visual environment into text keywords.
4. Audio Generation Engine
- AudioCraft (
audiocraft): Meta's open-source PyTorch library for deep learning research on audio generation. - AudioGen (
facebook/audiogen-medium): A 1.5B parameter autoregressive transformer model accessed via AudioCraft. It takes the text keywords generated by Ollama and synthesizes the ambient environmental.wavfiles (e.g., rain, wind, room tone).
5. Deep Learning Frameworks (Dependencies)
- PyTorch (
torch): The foundational machine learning framework required to run AudioCraft locally. - TorchAudio (
torchaudio): Used alongside PyTorch for tensor-based audio manipulation and saving the final.wavfiles. - TorchVision (
torchvision): Included as a standard dependency in the PyTorch environment for handling the underlying tensor math.
Reflection
As a design prototype, Acoustic Chronotope successfully demonstrates how complex multimodal AI can be packaged into an intimate, emotionally resonant user experience. By focusing on ambient background soundscapes rather than speech or music, the application provides a subtle trigger for memory recall without overriding the user's own imagination. The deliberate choice to run all models locally addresses the critical privacy concerns associated with personal journaling. Applying a tactile, editorial aesthetic to an AI tool proved that advanced machine learning interfaces do not have to feel cold or utilitarian; they can feel like a natural extension of our analog lives. The project validates the concept that synthesized environmental audio, guided by personal memories, can serve as a profound tool for cognitive reflection and emotional grounding.
What Worked
- The automated routing between text and image models successfully extracted highly descriptive soundscape keywords without requiring technical prompting from the user.
- The visual design successfully transformed the interface into a calming, journal style environment, highlighting the value of careful typography and color in AI tools.
- The audio generation model reliably produced evocative ambient textures that accurately matched the extracted emotional and environmental markers.
- The offline, local first architecture resonated deeply with the design intent of keeping personal memories entirely private and secure.
What Did Not Work / Limitations
- The reliance on local GPU resources for running vision models and audio synthesis simultaneously restricts accessibility for users on standard consumer hardware.
- The audio generation occasionally produces repetitive artifacts or abrupt endings within the 30 second limit, requiring further refinement in the generation parameters.
- No controlled psychological study was conducted to validate the actual enhancement of memory recall.
- The system is currently limited to static background audio and lacks the ability to spatialize the sound interactively based on user movement or spatial mapping.
- The technical focus on model integration limited deeper exploration into cataloging and organizing these acoustic memories into a broader, searchable library over time.
Github
calluxpore/Acoustic-Chronotope